MySQL-InnoDB-索引
索引类似于书的目录,目的是为了更快的找到某一页,索引本质上就是为了更快的查找到数据。
在计算机体系内,是数据结构来承接着这重要的工作。
数据结构
能够快速找到数据的数据结构,一般都是用时间复杂度来进行衡量,用大O来进行标记。
O(1) < O(logn) < O(n)
哈希表O(1)
哈希表的查找数据的时间复杂度最低,但是为什么没有用哈希表来当作数据库索引的基础结构呢?
那是因为哈希表有着自己的缺陷,哈希表不能找到某一个范围内的数据,然而在使用数据库的情况下,按照范围查找是相当频繁的。
但是在InnoDB存储引擎中,存储引擎内部使用到了哈希表,那就是根据热点数据建立起来的自适应哈希索引,用来降低时间复杂度,提升找到效率。
树O(logn)
B+树演变历程:二叉查找树 -> 平衡二叉树 -> B+树。
二叉查找树
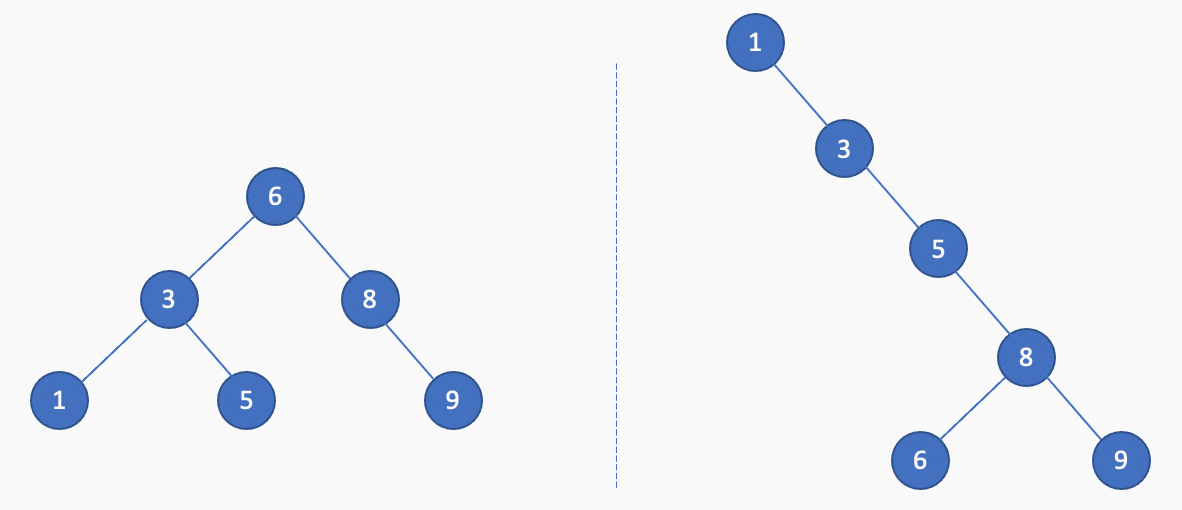
左右两个图都是二叉查找树。
如果是左边的图,最多三次就能找到。
如果是右边的图,最多需要5次才能找到,可能退化为单链表,时间复杂度降低为O(n)。
平衡二叉树
在满足二叉查找树的基础上,需要满足任何节点的两个子树高度最大差1。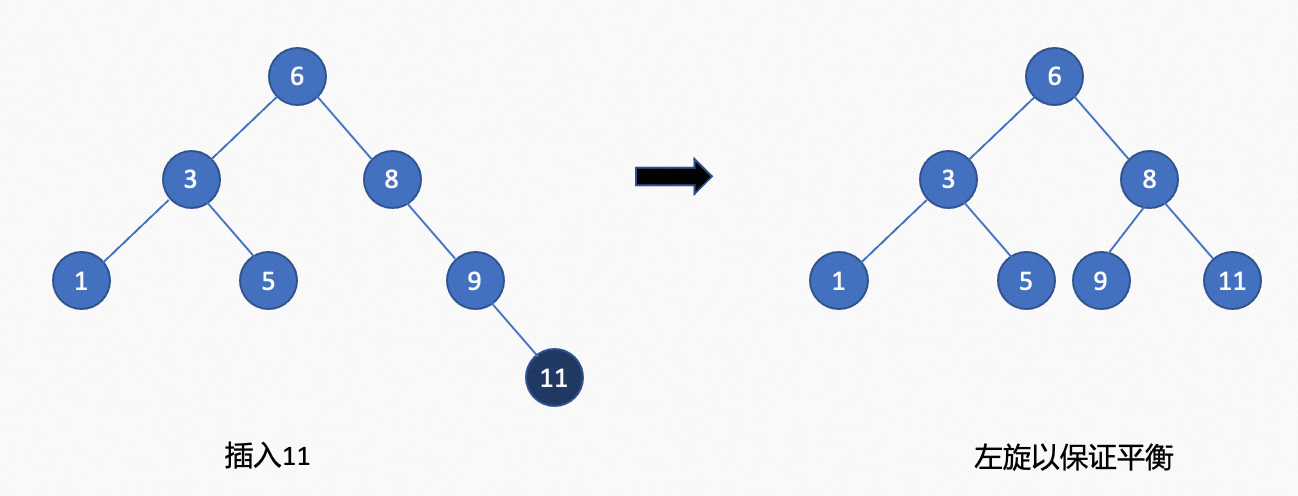
在插入节点11时,节点8的左子树高度为0,节点8的右子树高度为2,左右子树高度差为2 > 1(定义的1)
所以需要旋转进行调整,调整完成后。节点8的左子树高度为1,节点8的右子树节点高度为1。左右子树高度差 0 < 1 满足平衡二叉树的定义。
B+树
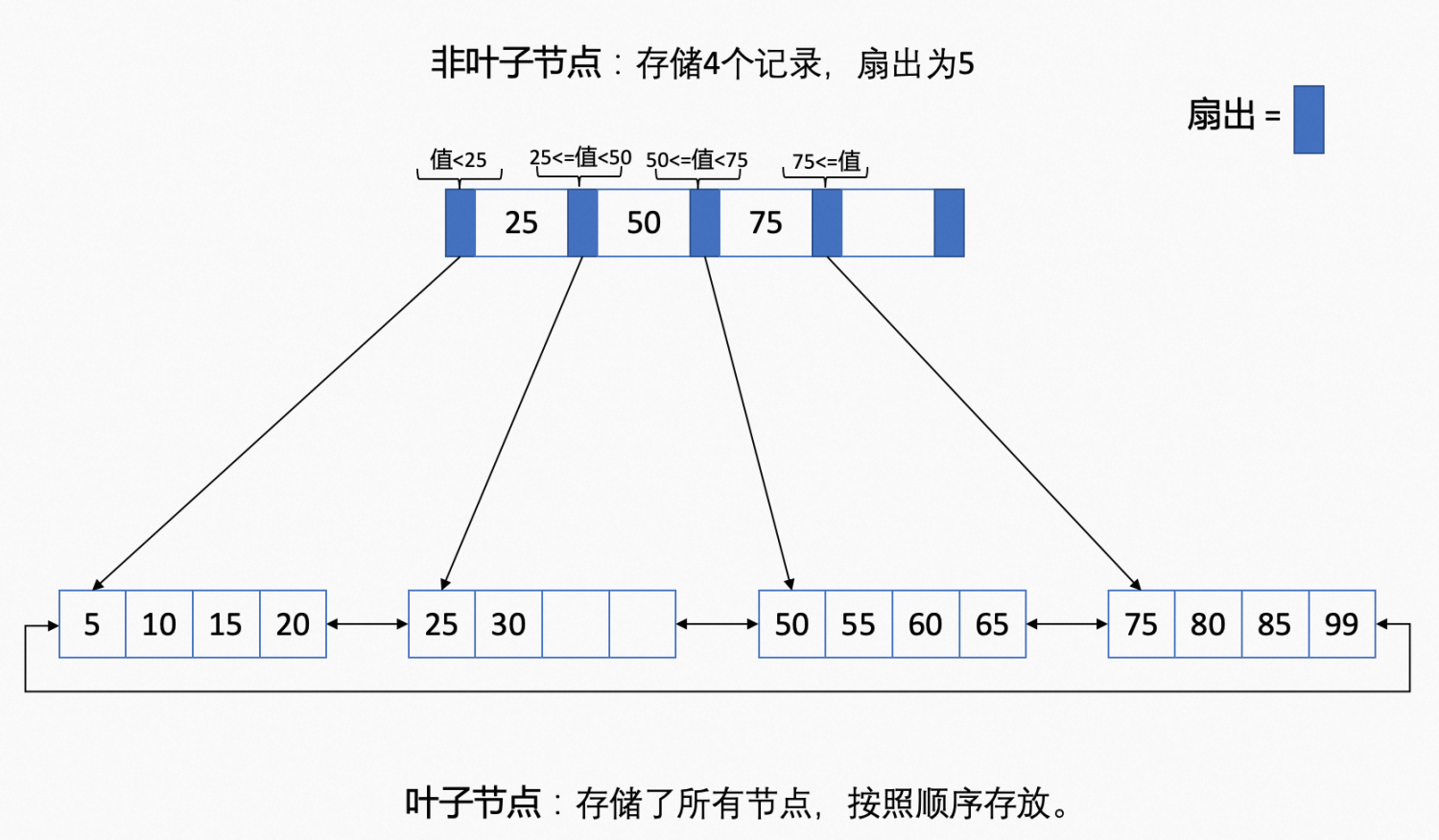
第一个扇出指向的叶子结点中的最大值 < 25
第二个扇出指向的叶子结点中的值范围 25 <= 值 < 50
第三个扇出指向的叶子结点中的值范围 50 <= 值 < 75
第四个扇出指向的叶子结点中的值范围 75 <= 值
B+ 树具有高扇出性,能够把整个B+树的高度降到很低。
为什么要降树的高度?因为每查找一个节点,理论上就要进行一次磁盘IO,树的高度越高,则查找的节点也越多,与磁盘进行IO次数也越多,那么耗时也会增加。一次磁盘IO大概在20ms左右。
在MySQL中一般树高在2到4层,那么非叶子节点能记录几百个叶子节点,扇出在几百左右。所以最多只需跟磁盘进行2到4次IO就可查到数据。
索引
这里介绍的是InnoDB的索引。 每一个索引都会创建一个B+树。 主键索引叶子节点存储的是数据,辅助索引叶子节点存储的是主键。
主键索引(Primary Key)
id:主键
name:建立了基于name的辅助索引
+----+-----------+-----+----------+
| id | name | age | location |
+----+-----------+-----+----------+
| 11 | 青龙 | 17 | 济南 |
| 15 | 小泽 | 16 | 西安 |
| 18 | 谷月 | 23 | 青岛 |
| 19 | 桂江亨 | 20 | 武汉 |
| 26 | 林青 | 40 | 武汉 |
| 35 | 高凡 | 29 | 深圳 |
| 39 | 帆帆 | 25 | 杭州 |
| 44 | 晴天 | 28 | 上海 |
|... | ... | ... | ... |
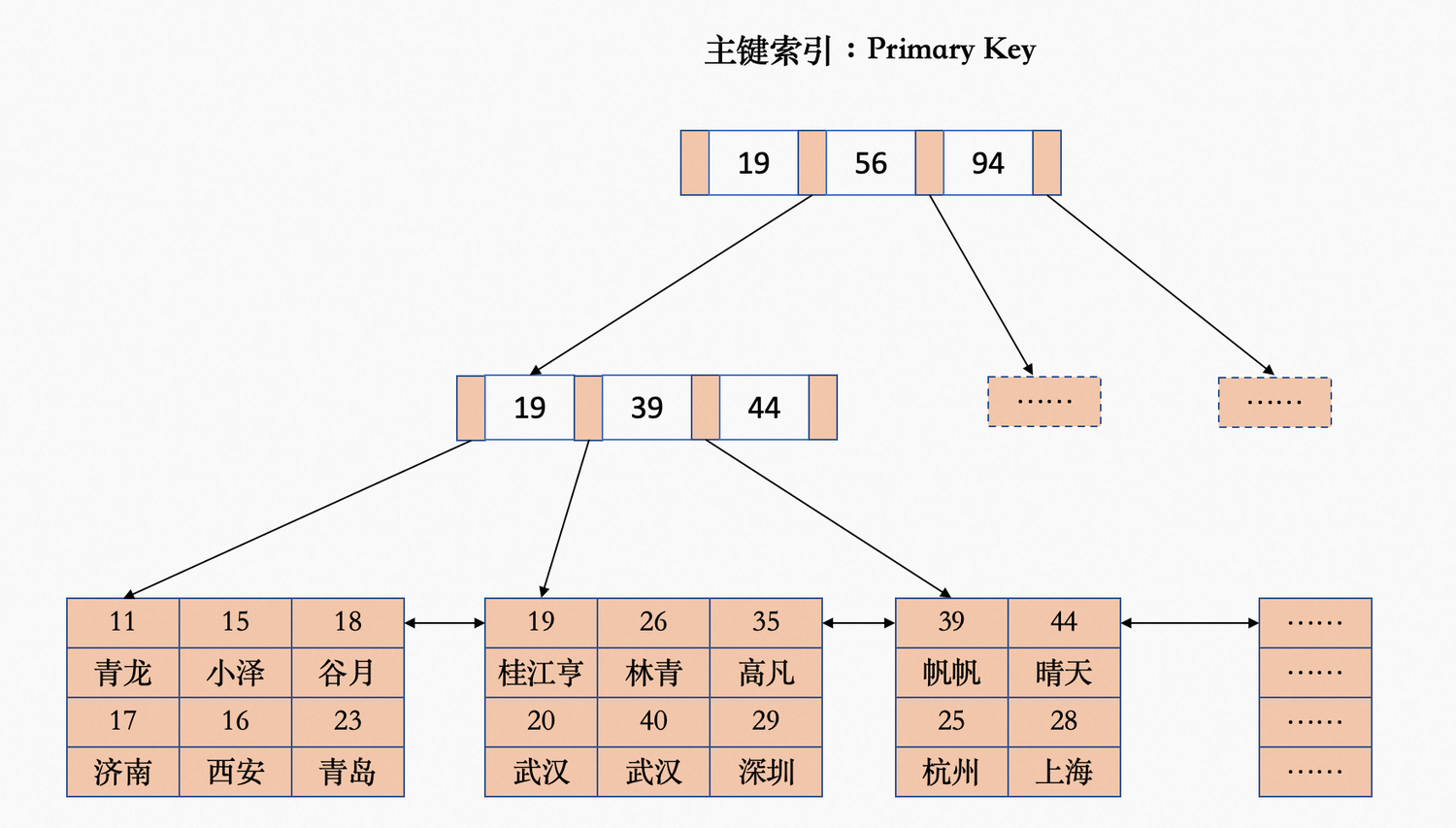
最下一层就是叶子节点,存储了所有的记录。最下层是一个双向链表。
叶子节点即是索引又是数据,所以称InnoDB的主键索引是聚集索引Clustered Index。
因此InnoDB的表必须有主键,如果没有显示指定主键,那么选个唯一索引作为主键,如果唯一主键也没有,那么系统会生成一个6字节长度的隐藏字段作为主键。
辅助索引(Secondary Indexes)
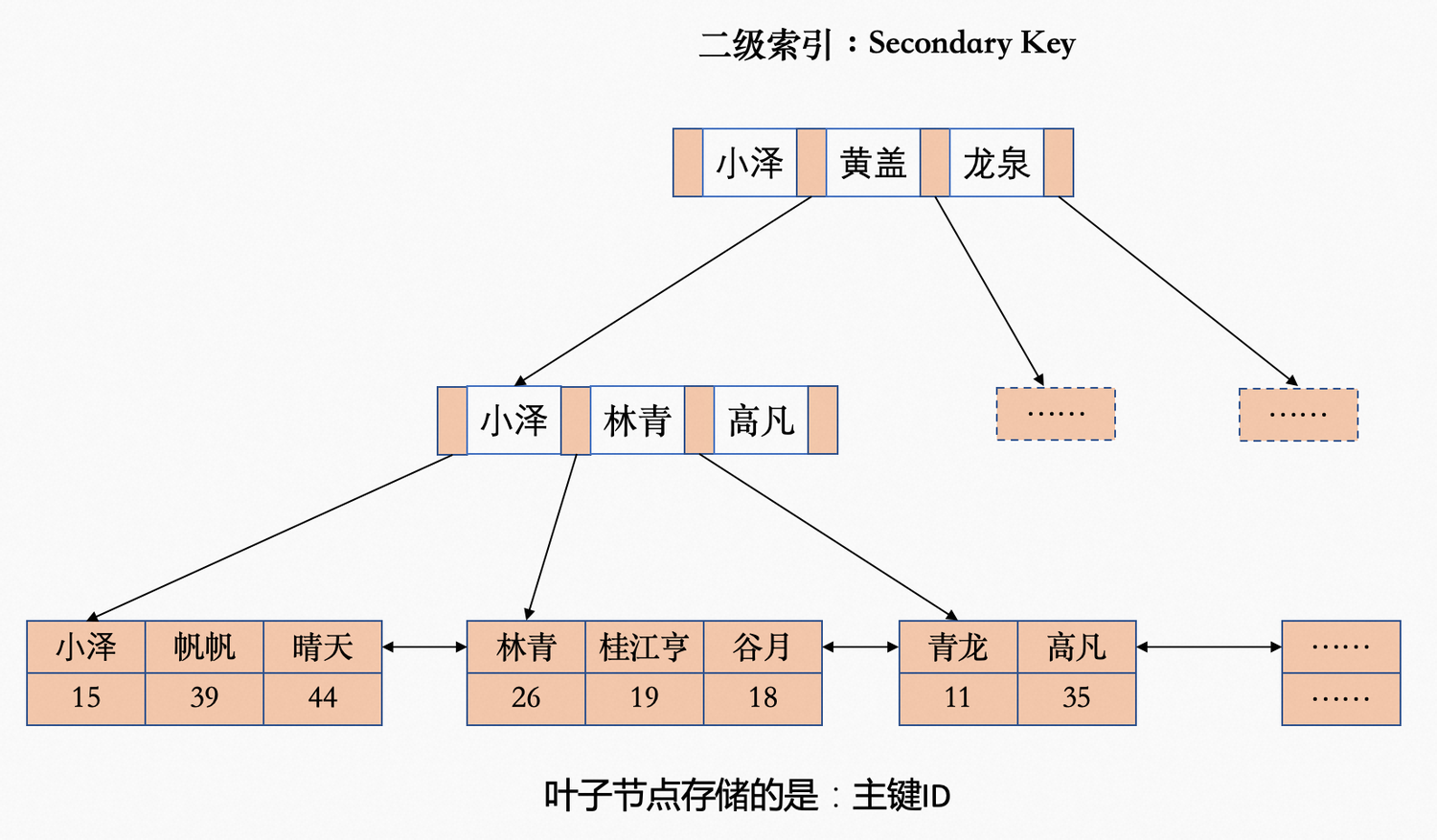
回表
若有这样的SQL语句 select * from user where name = '小泽';
执行过程分两步
第一步:会走name的辅助索引,最终拿到主键ID,值为15。
第二步:根据主键值15,会走主键索引,最终拿到这条数据。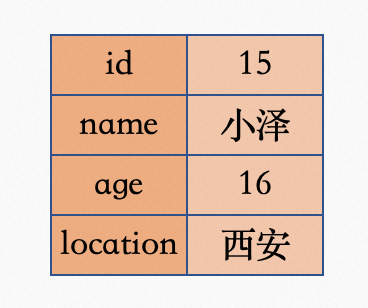
总结这条SQL语句共计走了两个索引,第二步走的主键索引就叫回表。
覆盖索引
若有这样的SQL语句 select id from user where name = '小泽';
执行过程只有一步
第一步:走name的辅助索引,最终拿到主键ID,值为15,直接返回就可以了。
这样就不用走主键索引了,这就叫做覆盖索引,或者称为索引覆盖。
联合索引
-- 创建的表t,建立了联合索引idx_a_b,a在前,b在后。
CREATE TABLE `t` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) NOT NULL DEFAULT '0' COMMENT 'a',
`b` int(11) NOT NULL DEFAULT '0' COMMENT 'b',
PRIMARY KEY (`id`),
KEY `idx_a_b` (`a`, `b`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 表t中存储的数据
mysql> select a,b from t;
+---+---+
| a | b |
+---+---+
| 1 | 1 |
| 1 | 2 |
| 2 | 2 |
| 2 | 4 |
| 2 | 6 |
| 3 | 1 |
| 3 | 3 |
| 4 | 2 |
| 4 | 5 |
+---+---+
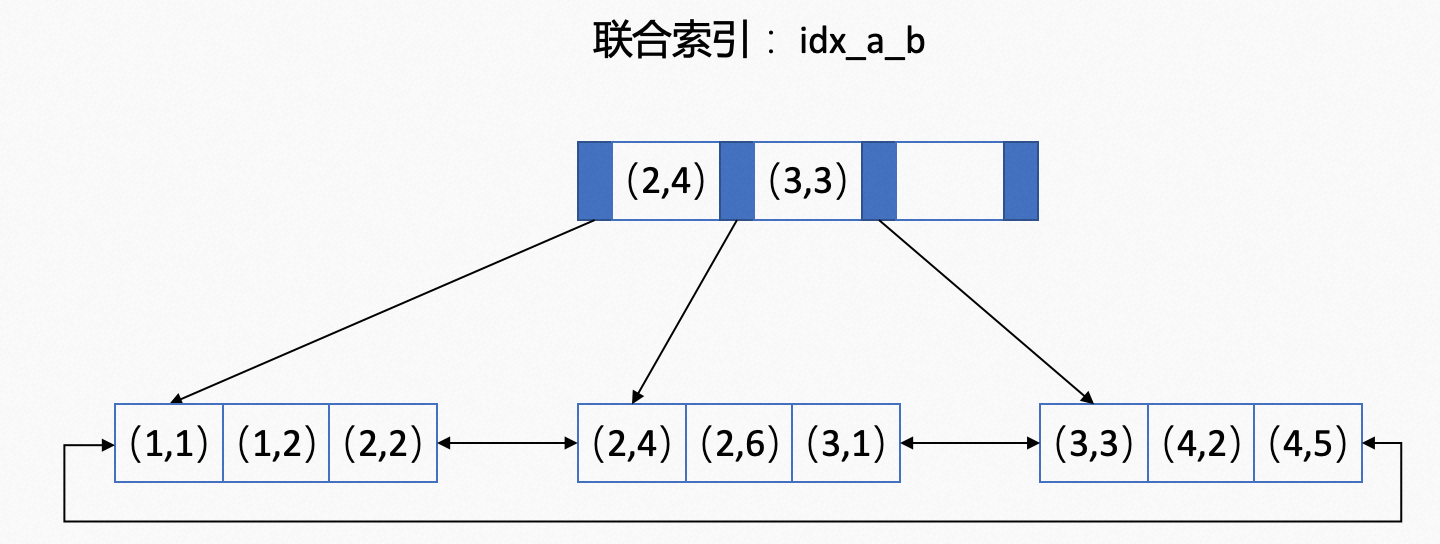
可以清晰的看出最下层,是以a先排序,然后b再排序。回答以下以下几个问题,更好的掌握下联合索引。
问:select a, b from t where a=2 and b=6; 是否有用到该联合索引?
答:用到了。可以通过explain关键字查看执行计划。
问:select a, b from t where a=2 order by b desc; 是否有用到该联合索引?
答:用到了。确定好了a之后,b本身就是有序的,因为是双向链表,从最后一个向前遍历就可以得到。
问:select a, b from t where b=2; 是否有用到该联合索引?
答:没有用到。因为b本身是无序的,可以通过explain关键字查看执行计划。
问:select a, b from t where a>2 and b=2; 是否有用到该联合索引?
答:有用到,但是只用到了联合索引中的a,没有用到b。根据a>2查出来(3,1) (3,3) (4,2) (4,5)共4个,但这并不是按照b顺序排列的,要遍历4个,才能获取到b=2的结果。
// 通过explain 可以清晰的看出,扫描的行数 rows 是 4,
mysql> explain select a, b from t where a>2 and b=2;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | t | NULL | range | idx_a_b | idx_a_b | 4 | NULL | 4 | 11.11 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
问:已经有联合(a,b)索引,还有必要单独建a索引,b索引吗?
答:没有必要单独建立a索引,它与联合索引(a,b)就是冗余的。 若有where b=?这样查询条件,是可以单独建立b索引的,因为直接where b= ?这样查询是使用不到联合索引(a,b)的。
:::info
如果在(col1, col2, col3)上有一个三列索引,则在(col1)、(col1, col2)和(col1, col2, col3)上有索引搜索功能。
:::
问:联合索引的情况是否会出现索引覆盖的情况?
答:会的,只要不去主键索引上查,就是索引覆盖。
索引最左匹配原则
在联合索引中,就是以最左为基准,依次向后可以用到索引。
在其他索引中,也是最左为基准的,例如建立一个name字段的索引,使用 like ‘张%’ 就可以使用到索引,因为左侧是确定的,如果使用 like ‘%张’,那是使用不到索引的。 %必须在后才能使用索引,也是遵循最左匹配原则。
查看表的索引
show index from table_name;
-- 一个user表,创建了几个索引,Cardinality越大,区分度越高,越有效。Cardinality越小,区分度越低,建的意义越小。
mysql> show index from user;
+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| user | 0 | PRIMARY | 1 | id | A | 126025 | NULL | NULL | | BTREE | | |
| user | 0 | u_id | 1 | u_id | A | 126025 | NULL | NULL | | BTREE | | |
| user | 1 | idx_name | 1 | name | A | 108607 | NULL | NULL | | BTREE | | |
| user | 1 | idx_answers | 1 | answers | A | 998 | NULL | NULL | | BTREE | | |
| user | 1 | idx_gender | 1 | gender | A | 1 | NULL | NULL | | BTREE | | |
+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
5 rows in set (0.00 sec)
高级索引知识
自适应哈希索引
这个是InnoDB存储引擎内部基于热点数据建立起来的哈希索引,将时间复杂度从O(logn)降低到O(1)。
参数innodb_adaptive_hash_index来控制是否开启,默认是开启的。
mysql> show variables like 'innodb_adaptive_hash_index';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| innodb_adaptive_hash_index | ON |
+----------------------------+-------+
1 row in set (0.01 sec)
可以通过show engine innodb staus来查看,运行情况。
mysql> show engine innodb status\G
......
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
...
1.59 hash searches/s, 2.93 non-hash searches/s --> 这里就是自适应哈希索引的运行情况
......
索引下推(ICP)
其实就是where条件直接下沉到存储引擎层进行直接过滤,而不是把数据返回到上层,再进行过滤。减少数据传输的时间,提升了效率。
参数optimizer_switch中的index_condition_pushdown控制了是否开启
mysql> show variables like 'optimizer_switch'\G
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,prefer_ordering_index=on
1 row in set (0.01 sec)
MRR
就是从Secondary Index查出来的主键,进行排序后,再去主键索引中查。
将随机IO改为顺序IO,提升了效率。
参数optimizer_switch中的mrr控制了是否开启
mysql> show variables like 'optimizer_switch'\G
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,prefer_ordering_index=on
1 row in set (0.01 sec)
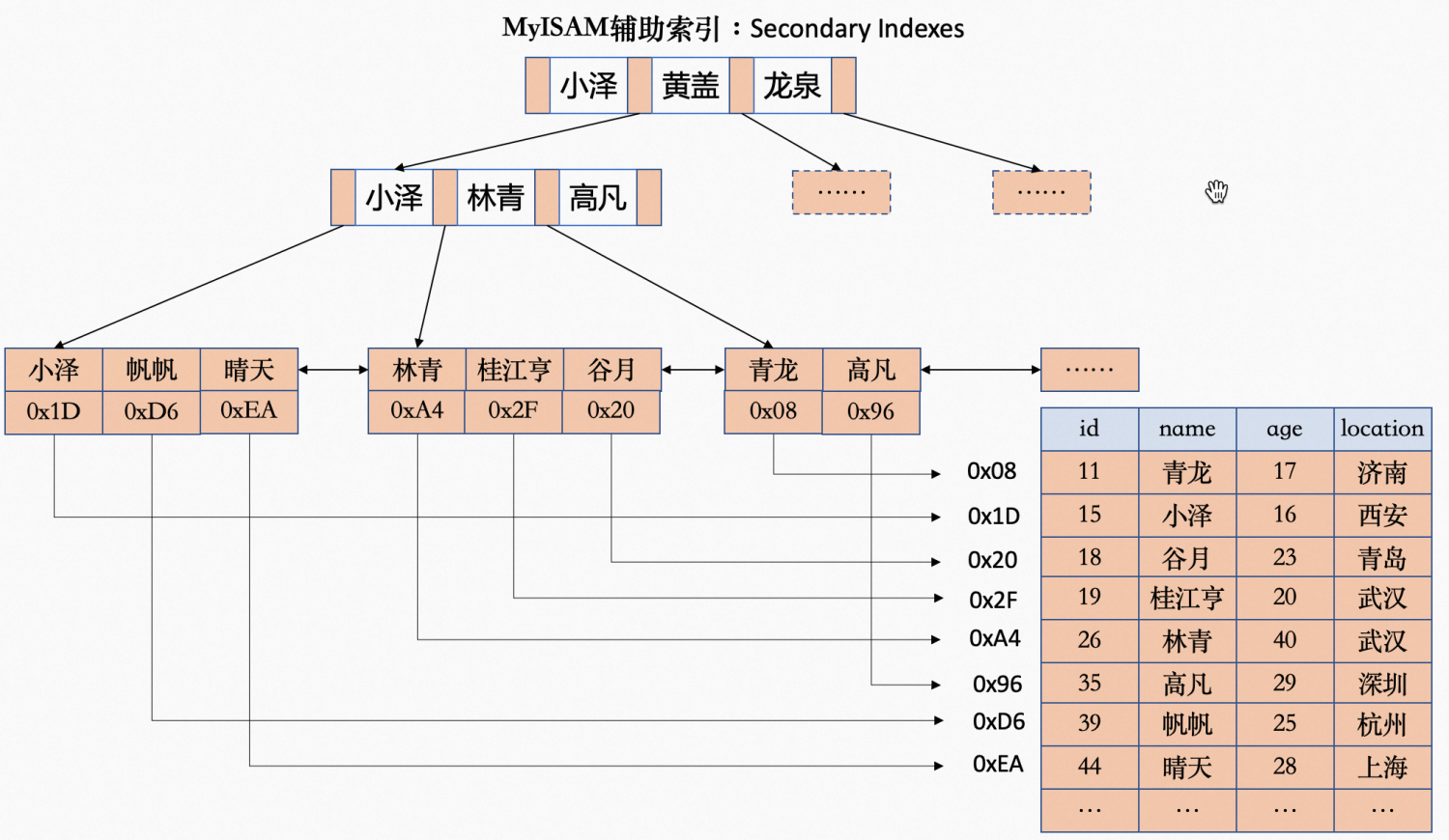
MyISAM存储引擎索引
主键索引(Primary Key)
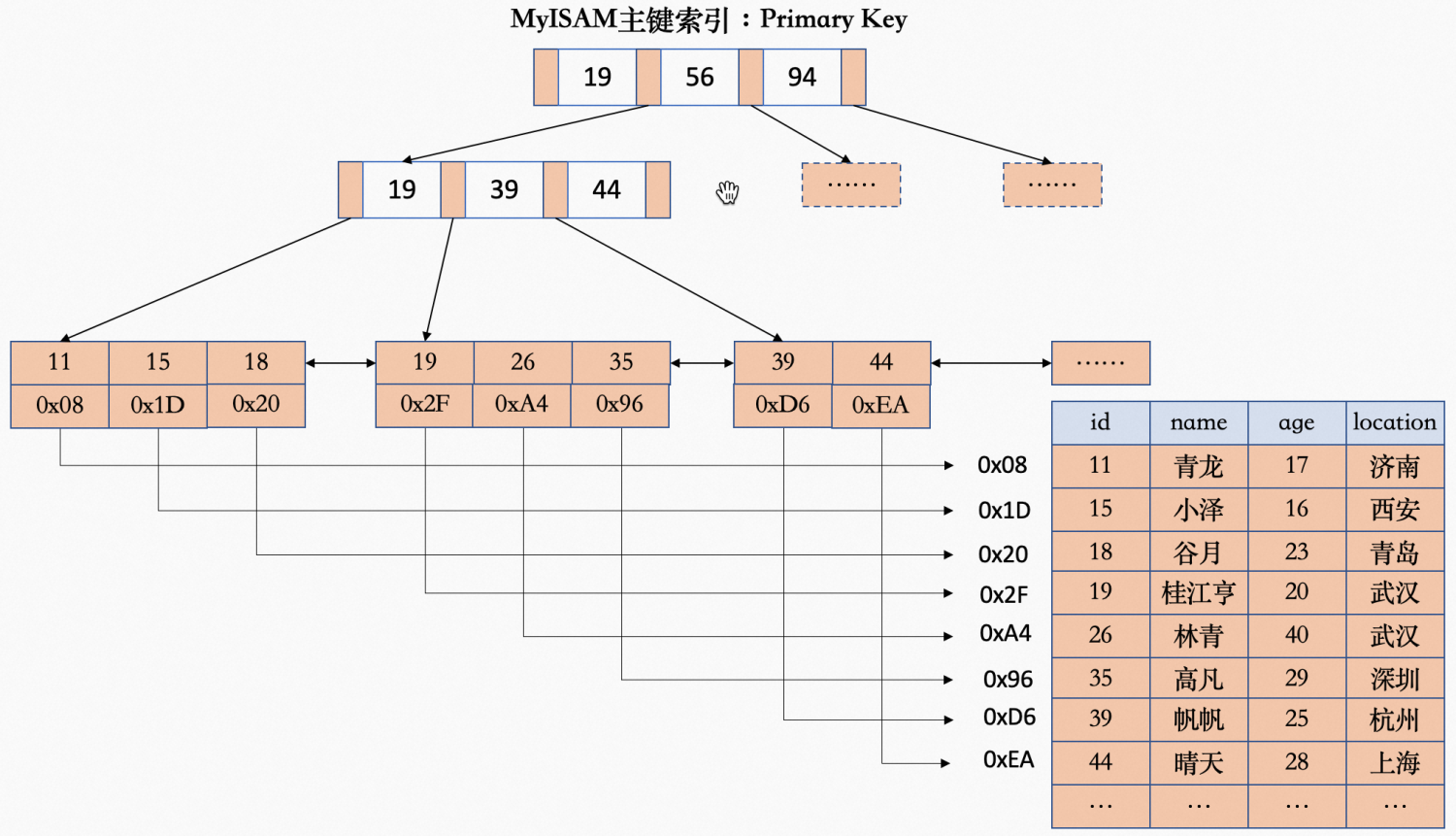
辅助索引(Secondary Indexes)
参考资料
https://blog.codinglabs.org/articles/theory-of-mysql-index.html
https://dev.mysql.com/doc/refman/5.7/en/
《高性能MySQL》第四版